Clang-format Tanks Performance
Let’s benchmark toupper implementations, because that’s a thing you do on Tuesdays.
Actually, I don’t really care about toupper much at all, but I was writing a different post and needed a peg to hang my narrative hat on, and hey toupper seems like a nice harmless benchmark. Despite my effort to choose something which should be totally straightforward and not sidetrack me, this weird thing popped out.
This will be a pretty short one - the longer, original post on the original, maybe far more interesting, topic is coming soon. The source is available on github if you want to follow along.
So let’s take a look at three implementations which perform toupper over an array of char: that is, which take an input array and modifies it in-place so any lowercase characters are converted to uppercase.
The first simply calls the C standard library toupper function1 in a C-style loop:
void toupper_rawloop(char* buf, size_t size) {
for (size_t i = 0; i < size; i++) {
buf[i] = toupper(buf[i]);
}
}
The second uses the more modern approach of using to std::transform to replace the raw loop:
void toupper_transform(char* buf, size_t size) {
std::transform(buf, buf + size, buf, ::toupper);
}
Finally, the third one is our bespoke ASCII-specific version that checks if the character lies in the range a - z and remaps it by subtracting 32 if so2:
void toupper_branch(char* buf, size_t size) {
for (size_t i = 0; i < size; i++) {
char c = buf[i];
if (c >= 'a' && c <= 'z') {
buf[i] = c - 32;
}
}
}
Seems straightforward enough, right?
Let’s benchmark these on my Skylake i7-6700HQ laptop, with the default gcc 5.5. Here’s a JPSP3 :

Let’s get three observations that aren’t really part of the story out of the way.
First, the pattern for the branchy algorithm (toupper_branch). It’s the only one that varies much at all with input size - the other two are basically flat. This turns out to be just a benchmarking artifact. I use random ASCII input4, so primary determinant of performance our branchy algorithm is branch prediction. For small input sizes, the branch predictor learns the entire input sequence across iterations of the benchmark and so mispredictions are low and performance is high, just like this. As sequence size grows the predictor memorizes less and less of the sequence until it flatlines when it mispredicts every time there is an uppercase character (0.27 mispredicts per character).
The second thing is this green blob of much slower samples from the toupper_branch in the upper left:
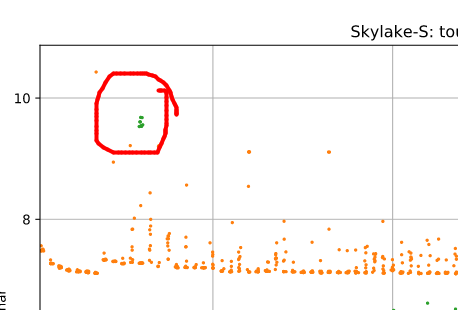
This wasn’t a one time artifact, I saw those guys hanging out up there across several runs. They don’t reproduce if you run that particular size alone however, only when the script runs to collect input across all size values. They don’t always show up. I didn’t look into it further but my best guess is some of unfortunate collision or aliasing effect perhaps in the branch predictor or in the 4k physical to virtual page mapping (VA space randomization was off, however).
The third not interesting thing is the bimodal behavior of toupper_rawloop – the blue dots form two distinct lines, at just above 2 cycles per char and a faster line at 1.5 cycles per char. All performance counters that I checked were the same between the two “modes”. The fast mode, which runs at 1.57 chars/cycle is basically bottlenecked on the load ports: there are 1.54 uops/cycle going to both port 2 and port 3, so those ports are 98% occupied. The slower mode I can’t explain.
While I was investigating it, the fast mode suddenly stopped appearing and I was stuck in slow mode. Maybe my CPU saw what I was up to and downloaded a microcode update in the background to remove the inconsistency, but I still have the SVG to prove it (for now).
So what’s the interesting thing?
The interesting thing is that the raw loop version runs 3x to 4x faster than the std::transform version: 1.5 to 2 cycles per character versus just above 7 cycles per character.
What’s up with that? Are my standard algorithms letting me down? Does std::transform have some fatal flaw?
Not really. Well, not at all.
It turns out these results occur when the functions are compiled in separate files. If you put them into the same file, suddenly the performance is is the same: they both run slowly.
No, it’s not an alignment thing.
It gets weirder too: the fast raw loop version, compiled in a separate file, slows down if you simply include the <algorithm> header. That’s right - including that header, which is never used and generates no code in the object file, slows down the raw loop by 3 to 4 times. Conversely, the std::transform version speeds up to full speed if you copy and paste the std::transform implementation out of <algorithm> and stop including that file.
It gets even weirder (this is the last “it gets weirder”, I promise): including <algorithm> doesn’t always do this. The slowdown happens if <algorithm> is included before <ctype.h>, but not if you swap them around:
Slow:
#include <algorithm>
#include <ctype.h>
Fast:
#include <ctype.h>
#include <algorithm>
In fact, in my case, this performance anomaly was triggered (in a different project) when clang-format sorted my headers, moving <algorithm> to the top where it belonged (hence the clickbait title).
Of course, we were going to end up mired in assembly at some point. Let’s not postpone the pain any longer.
Here are are the fast and slow versions of the functions5, with the core loops annotated:
<algorithm> included first:
toupper_rawloop(char*, unsigned long):
push rbp
push rbx
lea rbp, [rdi+rsi]
sub rsp, 8
test rsi, rsi
je .L1
mov rbx, rdi
.L5:
movsx edi, BYTE PTR [rbx] ; load a char from *buf
add rbx, 1 ; buf++
call toupper ; call toupper(c)
mov BYTE PTR [rbx-1], al ; save the result to buf[-1]
cmp rbp, rbx ; check for buf == buf_end
jne .L5 ;
.L1:
add rsp, 8
pop rbx
pop rbp
ret
With <algorithm> second:
toupper_rawloop(char*, unsigned long):
test rsi, rsi
je .L7
push rbp
push rbx
mov rbp, rsi
mov rbx, rdi
sub rsp, 8
call __ctype_toupper_loc
lea rsi, [rbx+rbp]
mov rdi, rbx
.L4:
movsx rcx, BYTE PTR [rdi] ; load a char from buf
mov rdx, QWORD PTR [rax] ; load the toupper table address (pointed to by __ctype_toupper_loc)
add rdi, 1 ; buf++
mov edx, DWORD PTR [rdx+rcx*4] ; look up the toupper result by indexing into table with the char
mov BYTE PTR [rdi-1], dl ; store the result
cmp rsi, rdi ; check buf == end_buf
jne .L4 ;
add rsp, 8
pop rbx
pop rbp
.L7:
rep ret
The key difference is the slow version simply calls toupper in the loop, while the fast version has no function calls at all, just a table lookup6 - the body of std::toupper has been inlined.
Examining the glibc source, we find the implementation of toupper:
__extern_inline int
__NTH (toupper (int __c)) // __NTH is a macro that indicates the function doesn't throw
{
return __c >= -128 && __c < 256 ? (*__ctype_toupper_loc ())[__c] : __c;
}
We see that toupper is implemented as an extern inline function that first checks that the range of the char fits within a byte7 and then looks up the character in the table returned by __ctype_toupper_loc(). That function returns a thread-local pointer (a const int **), which in turn points to a lookup table which given a character returns the uppercase version8.
So now the assembly makes sense: the fast version of the algorithm inlines the toupper body, but it can’t inline the __ctype_toupper_loc() call9; however, this call is declared __attribute__((const)) which means that its return value depends only on the arguments (and here there are no arguments) and so the compiler knows it returns the same value every time and so can be hoisted out of the loop, so the loop body has only a few loads associated with the lookup table, the store of the new value to the buffer, and loop control10.
The slow version, on the other hand, leaves the toupper() inside the loop. The loop itself is one instruction shorted, but of course you need to run all the code inside toupper as well. Here’s what that looks like on my system:
lea edx,[rdi+0x80] ; edx = rdi + 0x80
movsxd rax,edi ; zero extend c
cmp edx,0x17f ; check that c is in -128 to 255
ja 2a ; if not, we're done
mov rdx,QWORD PTR [rip+0x395f30] ; lookup TLS index
mov rdx,QWORD PTR fs:[rdx] ; access TLS at index
mov rdx,QWORD PTR [rdx] ; dereference TLS pointer
mov rdx,QWORD PTR [rdx+0x48] ; load current toupper lookup table
mov eax,DWORD PTR [rdx+rax*4+0x200] ; lookup c in LUT
2a:
ret
Since it’s a standalone function call, it has to do more work. There are no less than five chained (pointer-chasing) memory accesses. Only two of those accesses remained in the fast loop, because the rest were hoisted up and out of the loop. The input to output latency of this function is probably close to 25 cycles, so out measured throughput of ~7 cycles means that the CPU was able to run several copies in parallel, not too terrible all things considered.
Why does this happen?
Through a long series of includes, C++ files like <algorithm> include <bits/os_defines.h> which has this line:
// This keeps isanum, et al from being propagated as macros.
#define __NO_CTYPE 1
When <ctype.h> is ultimately included, this prevents the block containing the extern inline definition of toupper from being included:
#if !defined __NO_CTYPE
# ifdef __isctype_f
__isctype_f (alnum)
// lots more like this
__isctype_f (xdigit)
# elif defined __isctype
# define isalnum(c) __isctype((c), _ISalnum)
# define isalpha(c) __isctype((c), _ISalpha)
// more like this
# endif
// the stuff we care about
# ifdef __USE_EXTERN_INLINES
__extern_inline int
__NTH (tolower (int __c))
{
return __c >= -128 && __c < 256 ? (*__ctype_tolower_loc ())[__c] : __c;
}
__extern_inline int
__NTH (toupper (int __c))
{
return __c >= -128 && __c < 256 ? (*__ctype_toupper_loc ())[__c] : __c;
}
# endif
// here's where tolower is defined as a macro
# if __GNUC__ >= 2 && defined __OPTIMIZE__ && !defined __cplusplus
# define tolower(c) __tobody (c, tolower, *__ctype_tolower_loc (), (c))
# define toupper(c) __tobody (c, toupper, *__ctype_toupper_loc (), (c))
# endif /* Optimizing gcc */
#endif /* Not __NO_CTYPE. */
Note when including <ctype.h> from C++ toupper is never defined as a macro - at most it is extern inline - the macro definitions below that are guarded by !defined __cplusplus so they’ll never take effect.
So I’m not sure if the extern inline bodies of tolower and toupper are intended to be excluded by __NO_CTYPE in this case, but that’s what happens and this has a significant performance impact in this toy loop. As a corollary, if you include <cctype> rather than <ctype.h> (the C++ version of the C header which puts functions in the std:: namespace) you also get the slow behavior because <cctype> ultimately includes <bits/os_defines.h>.
Does this matter? Nah, not the performance bit anyway.
toupper is broken for serious multilingual use and, if you only care about ASCII you can write your own faster function. If you care about proper text handling, you are probably using UTF-8 and you’ll have to use something like ICU to do locale-aware text handling, or wait for C++ to get Unicode support (you might be waiting a while). It’s only interesting in clickbait sense of “clang-format can cause a 4x performance regression”.
On the other hand, I suspect that including standard headers in different orders should not change the declarations like that, and there are other differences beyond toupper and tolower. That’s probably a bug, so I have filed one against libstdc++. So while we can hope this specific issue might be fixed in the future, no doubt the scourge of include order affecting semantics will be with us more or less forever.
Does this happen on all libc versions? Mostly yes, but it gets complicated.
The above results apply directly to gcc 5.5 and glibc 2.23, since that’s what I used, but things get weirder on newer versions (starting around glibc 2.27). On newer versions, the issue as described above occurs between <algorithm> and <ctype.h>, but additionally <stdlib.h> enters the picture11: if you include <stdlib.h> before <ctype.h> you’ll enter slow mode, which doesn’t happen on earlier versions. So apparently <stdlib.h> also ends up defining __NO_CTYPE at some point on these newer versions12. At least here we can’t blame clang-format sorting – it might fix the issue for by sorting headers (in files where you aren’t including any other problematic header).
Comments
You can leave a comment below.
This post was also discussed on Hacker News and lobste.rs.
Thanks
Thanks to HN user ufo who pointed out you don’t need a lambda to adapt std::toupper for use in std::transform, and Jonathan Müller who subsequently pointed out that in fact you do want a lambda.
Thanks to Andrey Semashev who pointed out in the comments some additional details of what’s going on and recommended re-filing the bug against libstdc++ rather than glibc.
If you liked this post, check out the homepage for others you might enjoy.
-
Yes,
toupper(3)from<ctype.h>is basically irreparably broken for most non-ASCII use, because it cannot handle multibyte characters, but it is good enough for our purposes. We only feed it ASCII strings. ↩ -
ASCII conveniently locates lowercase and uppercase characters 32 positions apart, meaning that converting between then is a simple matter of adding or subtracting 32. In fact, if we were sure that all our input were ASCII letters, we could just unconditionally clear the 5th bit, e.g.
c & 0b11011111, which would lower any uppercase and leave lowercase unchanged. Of course, we can’t rely on inputs to be letters, so we need the range check to avoid clobbering non-lettercharvalues. ↩ -
Err, that would be a Jittered Performance Scatter Plot. This is basically a scatter plot with some interesting parameter on the x-axis (in this case, the size of the input) and performance (in this case, cycles per character, lower is better) on the y-axis. The main feature is that each x parameter value is sampled multiple times: here the benchmark is repeated 10 times for each size ↩
-
In particular, characters are chosen uniformly at random in the range
[32, 127], so the if statement in the function is true ~27% of the time. ↩ -
Specifically, I’m showing the generated code in both cases for the raw loop version, the only difference being the order of include of
<algorithm>and<ctype.h>. The source generated is basically the same for all the fast and slow variants: e.g., thestd::transformversion generates basically the same slow and fast assembly as shown if you use it through<algorithm>or “copy and paste”, respectively. ↩ -
Even the fast loop isn’t as fast as I could be, as the lookup table pointer is redundantly reloaded (
mov rdx, QWORD PTR [rax]) inside the loop. That table pointer would change when the locale changes, but it is not updated during the loop so it could be hoisted. Perhaps the compiler can’t prove that because we are writing achararray (which could in principle alias[rax], the table pointer), but even__restrict__doesn’t help. A different version of the loop which just sums thetouppervalues and doesn’t write to a char array does receive this optimization - the load of the pointer is moved outside the loop. ↩ -
This range check doesn’t leave in the trace in the inlined assembly, because the compiler already knows that
charvalues will always fall in the range[-128, 255]- it is needed only because the API totoupper(c)takes anintvalue rather thancharso people could pass any oldintvalue but the lookup tables are only sized forchar, so this check is needed to avoid out-of-bounds accesses. ↩ -
Incidentally, this shows why the
std::toupperroutines don’t show any dependence on input size: they don’t use branches (except for the range-check branches which will predict perfectly), but rather a branch-free lookup table. ↩ -
This call could not be inlined even if you wanted to: its body is not available in the header. ↩
-
A simple lookup table will be faster than the “fast” version using
std::touppersince it doesn’t have to mess around with the extra indirection to get to the table.toupper_lookupillustrates this approach and runs at 1.32 cycles per byte. Of if you really cared about this, a vectorized approach would be at least 10x as fast again. ↩ -
I’m not really picking on
stdlib.h(or<algorithm>for that matter) - it is entirely likely that all C++ headers, and possibly many more C headers also trigger the behavior, but I didn’t test for that. I was includingstdlib.hjust to get the definition forsize_t. ↩ -
So yes, it happens because newer stdlib.h, when included from C++, actually includes not the “C” stdlib.h, but a C++ stdlib.h override file which includes a bunch of stuff including
<bits/os_defines.h>before ultimately including the base “C” stdlib.h. ↩
Comments
I have commented on the bug you linked (https://sourceware.org/bugzilla/show_bug.cgi?id=25214#c4). Looks like a libstdc++ issue caused by it inconsistently overriding C headers. And IMHO it is worth requesting libstdc++ to implement the same optimization glibc does in order to make locale functions inlinable.
Thanks Andrey. Yes, it looks like when you include
ctype.hthere is no override for it in libstdc++, so the usual C version is used, but things like stdlib.h do have overrides (and the override results in a different definition).I’ll comment further on the glibc issue.
It looks like you have a comment system now, no?
How did you get comments? Something like this maybe?
https://jekyllcodex.org/blog/gdpr-compliant-comment/
You are right, since I wrote that I have added a comments system … and it was quite a chore!
I used staticman and I documented the process in a blog post.